REEL LCI
Repository of Electronics Environmental Line-items
Disaggregated, process-level life cycle inventory data for electronics — built for hotspot analysis across the full component stack.
About the Database
Process-level LCI data for electronics
REEL provides disaggregated, cradle-to-gate unit process inventories across the full electronics component stack — from 3nm logic wafers to passive components, PCBs, and rack-scale infrastructure. Every dataset breaks down into individual process steps, enabling hotspot analysis at a level of detail that aggregated databases can't offer.
300+ datasets spanning 18 component categories, each with complete material, energy, water, and emissions flows.
Unlike proprietary databases, REEL is built entirely from publicly available information: academic papers, equipment vendor specifications, corporate sustainability reports, and engineering calculations. Every assumption is documented and independently verifiable.
Database Coverage
18 categories, 300+ datasets
From advanced 3nm logic to commodity passives, the database covers the full spectrum of electronics components found in modern IT equipment.
Semiconductor depth
Each wafer model contains a complete, step-by-step process flow mapped to individual equipment operations. For example, a 7nm FinFET wafer model includes:
v0.1 datasets now available on Circa
REEL LCI v0.1 is published on Circa as process-level (disaggregated) datasets. This means you get the full elemental flows and material inputs for each unit process, ready to integrate into your LCA model.
What's included: Gate-to-gate unit process inventories with all direct inputs (energy, water, chemicals, gases) and outputs (emissions, waste) for 300+ electronics datasets.
What you'll need to add: Upstream process nodes from background databases (ecoinvent, Carbon Minds, etc.) need to be connected manually on top of the material inputs.
Coming next: Aggregated (system-level) datasets with all upstream burdens pre-calculated will be available in a future release.
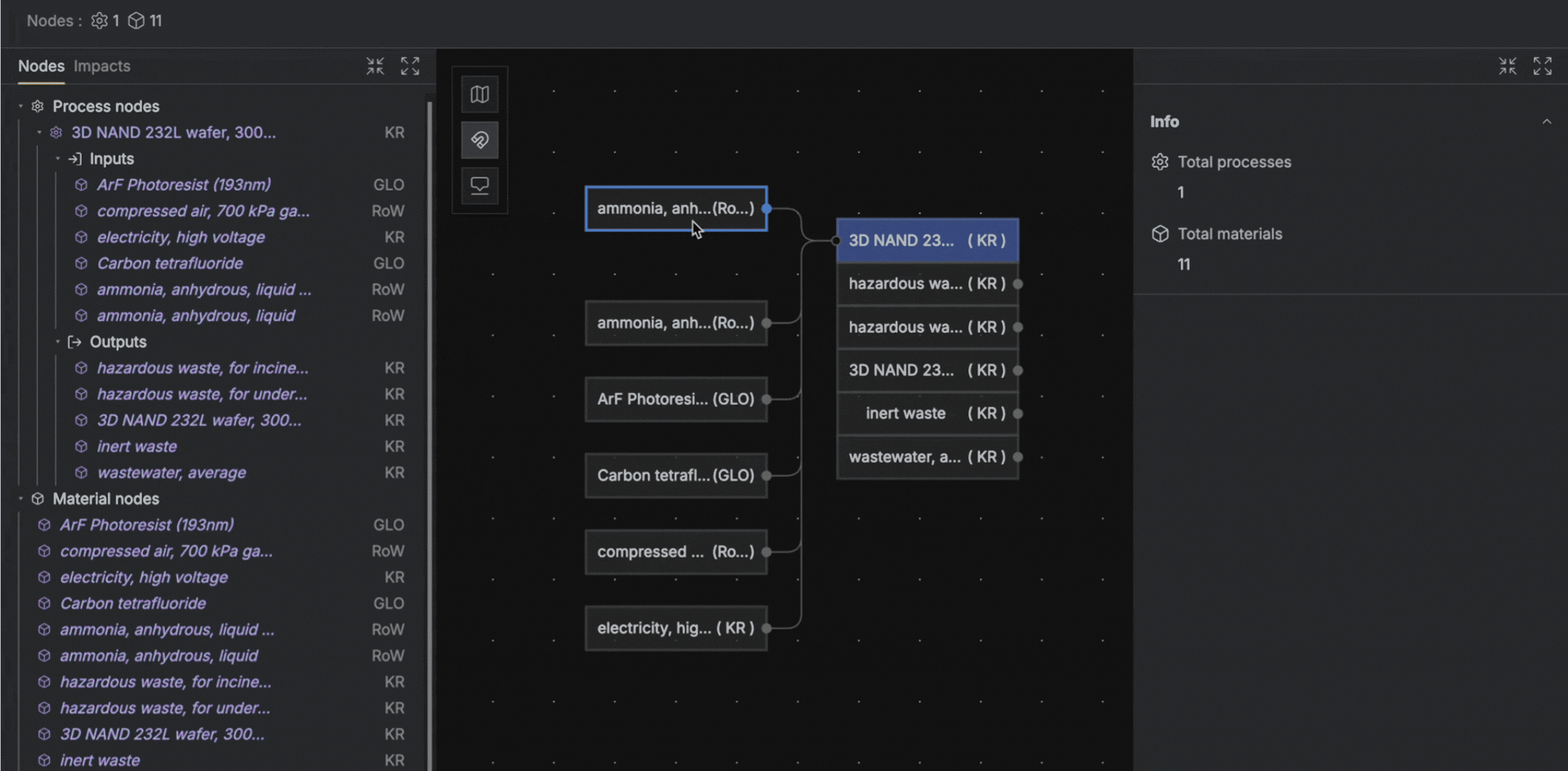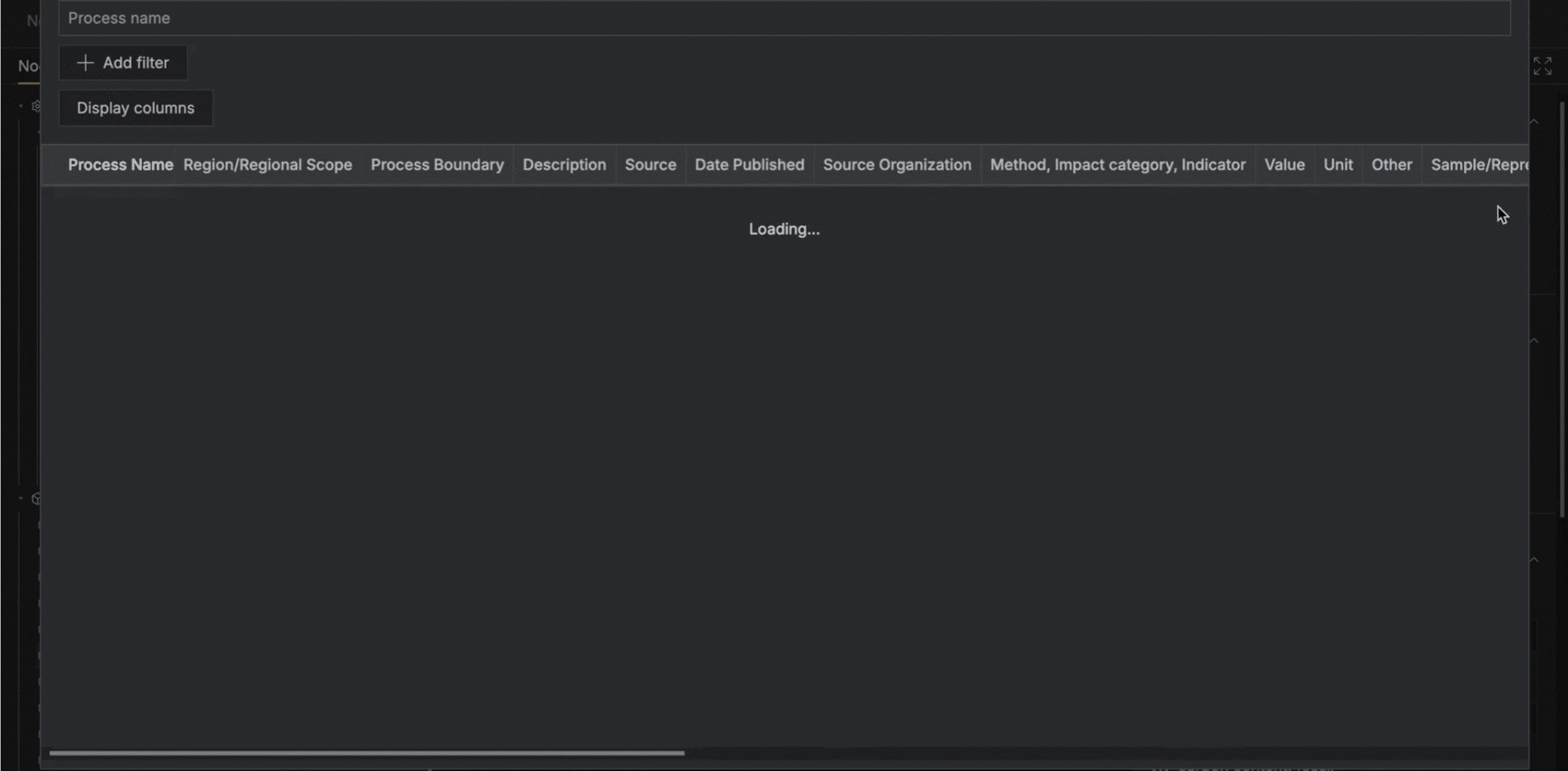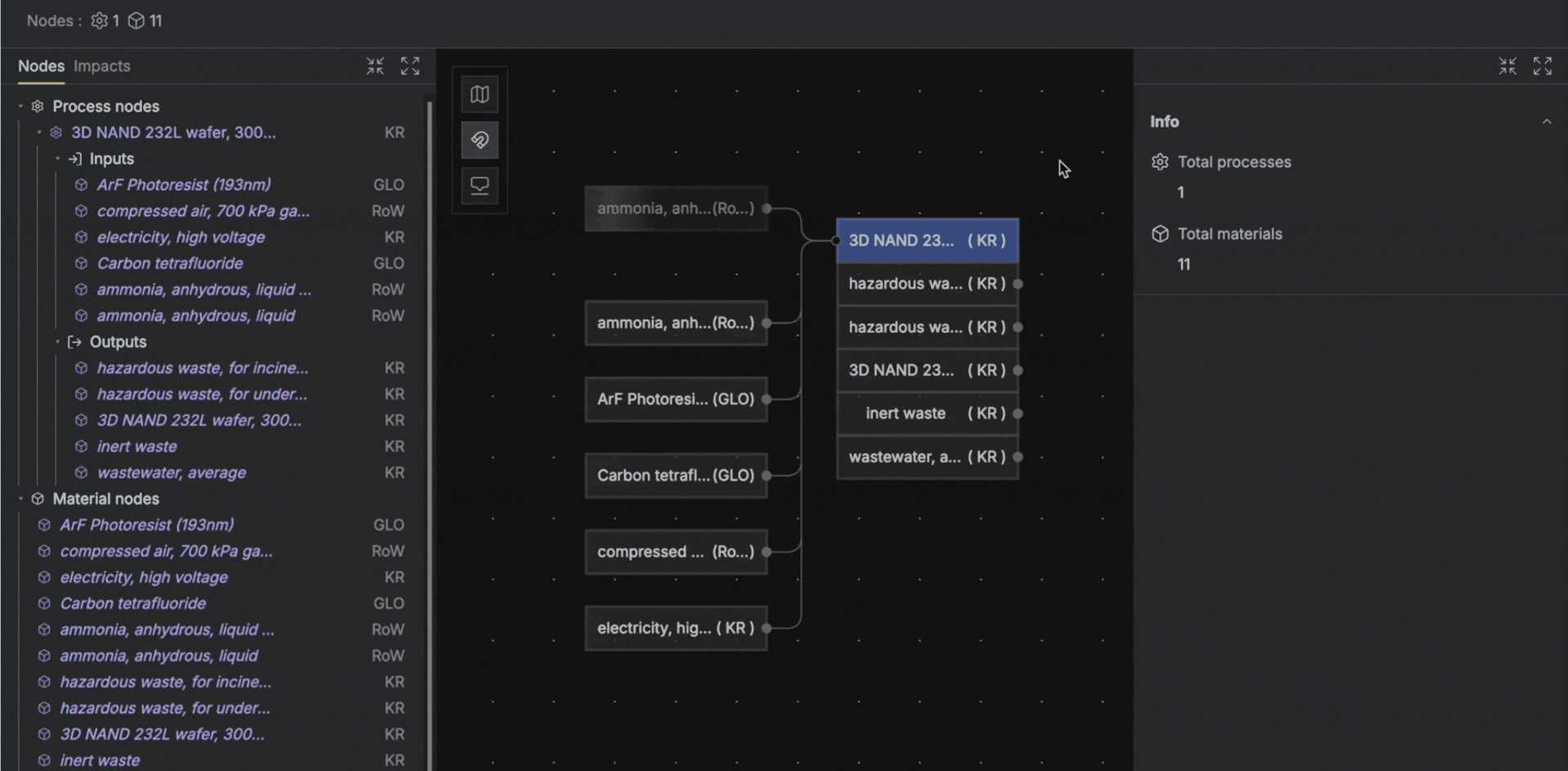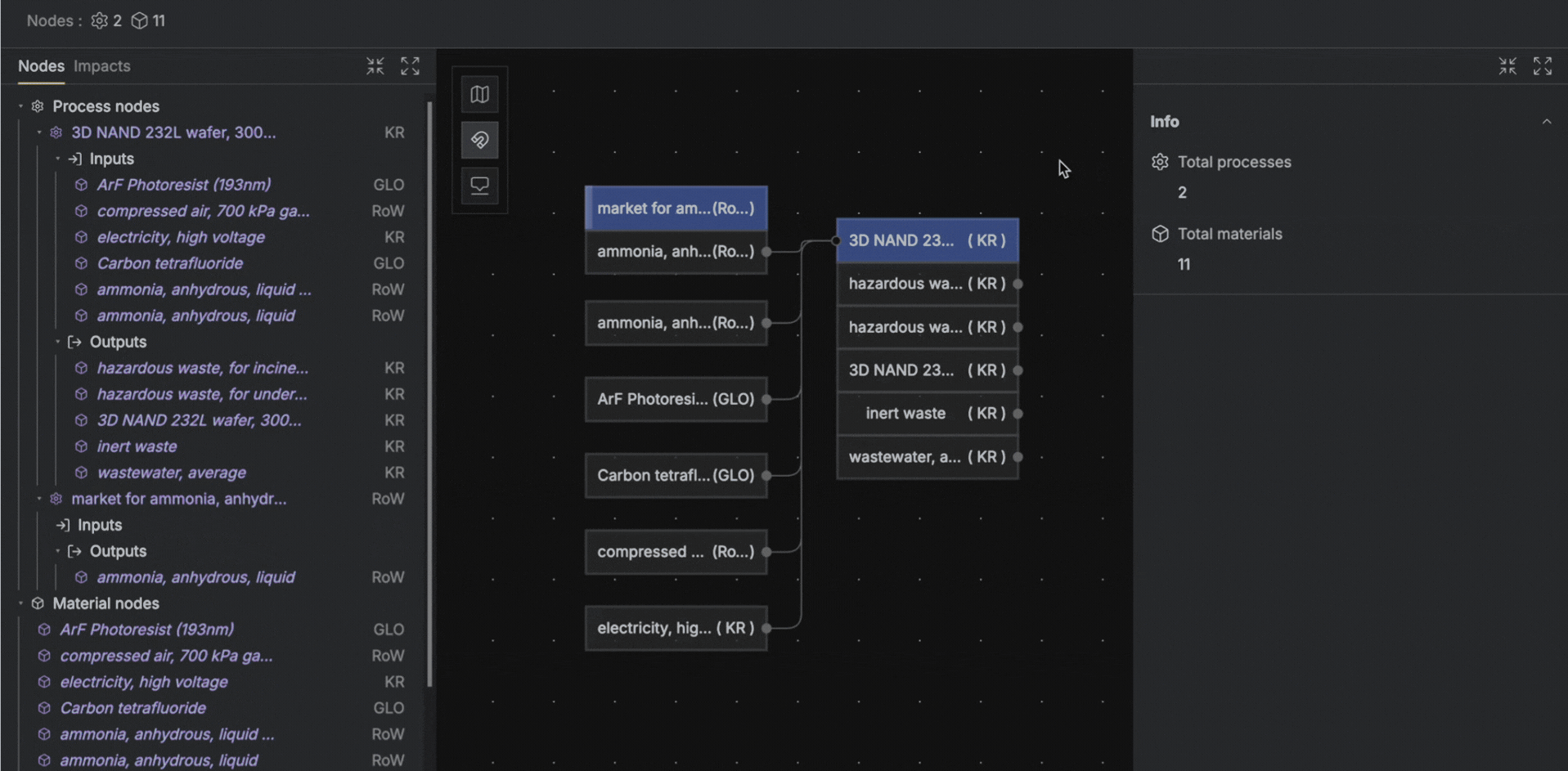
Adding upstream process nodes to material inputs in Circa
How It Works
The virtual factory approach
Instead of relying on proprietary facility measurements, we construct detailed inventory models bottom-up - from equipment specs, process chemistry, and publicly documented parameters.
Public Sources
Equipment specs, academic papers, patents, sustainability reports
Process Models
Per-operation inventories: energy, materials, chemicals, emissions
Calculation Engine
Aggregation with uncertainty propagation, yield adjustments, allocations
LCI Datasets
Gate-to-gate unit process data with ecoinvent-compatible flow mapping
What the inventory tracks
Methodology Report
Full documentation of data and methods
The methodology report is informed by ISO 14040/14044 guidance and documents every aspect of the database: system boundaries, allocation procedures, data quality indicators, and sector-specific modeling approaches.
The report is intended for LCA practitioners who need to evaluate data quality, understand assumptions, and appropriately apply the inventory data in their assessments.
REEL LCI Methodology Report
Version 0.1
A Note on AI
How we used AI in this project
We used large language models (Claude Opus 4.5/4.6 and Gemini 3 Pro Deep Research) extensively as a research assistant throughout the development of REEL. Here's what that means in practice.
What AI helped with
- Collecting and synthesizing equipment specifications, patents, and academic papers across hundreds of semiconductor processes
- Extracting quantitative data from published sources into structured YAML process files
What AI did not do
- Generate or fabricate any data - every value traces to a documented source or explicit engineering estimate
- Make methodological decisions - system boundaries, allocation rules, and modeling choices are human-directed
- Perform the final LCI calculations - the deterministic Python engine handles all aggregation, yield adjustment, and unit conversion
- Validate results without review - all outputs were checked against published benchmarks
In short: AI/LLM solutions dramatically accelerated the research and engineering work that would have taken a team of specialists many months. But the data itself comes from real, citable sources, the calculations are deterministic code, and the quality control is human. We think this is a reasonable and productive way to use the technology, and we'd rather be upfront about it.
FAQ
Frequently asked questions
An LCI quantifies all the inputs (energy, water, materials) and outputs (emissions, waste) associated with a product's manufacturing. It's the data layer underneath impact assessments like carbon footprinting. REEL provides this raw inventory data - users apply their own impact assessment methods (e.g., IPCC GWP factors) to convert to characterized results like kg CO2e.
The database uses uncertainty ranges (min/typical/max) to reflect data quality. Results are validated against published fab-level benchmarks from corporate sustainability reports and academic meta-studies. Our methodology report documents a formal data quality framework with indicators for reliability, completeness, temporal relevance, and technological specificity. Where gaps exist, they are clearly flagged.
The methodology is informed by ISO 14040/14044 guidance for life cycle assessment. Elementary flows are mapped to ecoinvent nomenclature for interoperability, and emissions use standard compartment/subcompartment classifications. Waste treatment is mapped to ecoinvent activity datasets. This allows downstream users to integrate REEL data with ecoinvent background systems.
The database can support Scope 3 Category 1 (Purchased Goods) accounting for electronics by providing manufacturing inventory data for embodied impact assessments. However, REEL provides cradle-to-gate unit processes - users must connect to background datasets (e.g., ecoinvent for electricity grids and upstream materials) and apply appropriate LCIA methods for their specific supply chain geography. As a v0.1 release, we recommend cross-checking key results against other available sources.
Default datasets assume high-volume manufacturing in the region most representative for each technology: Taiwan for advanced logic wafers, South Korea for memory, and China for PCBs and passive components. Electricity grid mixes, water treatment practices, and facility-level parameters all reflect these defaults. Production volumes assume large-scale commercial fabrication. These assumptions significantly influence results - practitioners should always evaluate whether they match their specific supply chain context.
From the author
Latest Insights
Guidance for Practitioners
Always perform sensitivity analysis
Three parameters have an outsized influence on results. We strongly recommend testing your conclusions against variations in each.
Geography
Electricity grid mix is often the single largest driver of characterized impacts. A fab in Taiwan vs. Germany vs. the US can substantially shift carbon intensity depending on the grid mix used. Default datasets assume region-specific grids - adjust the electricity input to match your actual supply chain.
Yield
Yield assumptions vary by technology and maturity. Advanced nodes (3-7nm) use lower default yields than mature nodes (28nm+), reflecting publicly reported ranges. Because yield affects per-die allocation of all upstream inputs, even modest changes can meaningfully shift results - particularly for advanced packaging where stacking yields compound.
Production Volume
Facility overhead (HVAC, ultrapure water systems, abatement) is allocated across production volume. Default assumptions vary by technology maturity and available data - leading-edge fabs use published capacity figures, while mature nodes rely on industry averages. Lower utilization rates increase per-unit burdens, so the assumed scale of production matters.
We are working with Circa to enable granular, easy adjustments around these parameters directly in the platform. For now, practitioners should manually scale the relevant inputs and outputs to reflect their specific scenario.
Data Feedback
Help improve the database
Found an inconsistency, missing value, or data error? Let us know. Your feedback helps improve the quality and reliability of the REEL LCI database for everyone.
For partnerships, citations, or other inquiries, email [email protected].
Access the Data
Ready to use REEL LCI data?
The database is available through Circa, a platform for sharing and managing LCA data, where you can browse, search, and integrate REEL LCI datasets into your LCA models.
Browse on Circa.ai
Authored by
Jonathan Balsvik
LCA practitioner focused on the electronics sector. Jonathan has delivered life cycle assessments and product carbon footprints for a range of hyperscalers and companies across the semiconductor value chain.
REEL was created to make up-to-date, component-level electronics LCI data more broadly available, supporting both industry practitioners working on product carbon footprints and academic researchers advancing the field.
Connect on LinkedIn